¿Por qué es necesario Git?
Hace mucho mucho tiempo cuando los desarrolladores editaban código la única manera que tenían de hacer copias de seguridad sobre sus archivos era hacer una copia en otro directorio 📁 en algún momento. Esta acción era algo recurrente pero cuando los proyectos crecían y se dilataban en el tiempo acaba siendo un caos saber qué versión correcta, creando un autentico quebradero de cabeza encontrar la versión del código correcto.

No es infrecuente que al hacer una modificación se deban refactorizar ( ⬅️ ojo al palabro bro! ) algunos archivos, quizás 2 o 3 únicamente si el cambio es pequeño y puede que además, paralelamente se esté trabajando en otra característica del software que se encuentre en otro directorio diferente (recuerdo que ese dir contendría todos los archivos en algún momento del pasado). Si queremos incluir el código correspondiente de esa mejora en una versión posterior seguramente no puedas ya que el código sobre el que lo quieres aplicar ha cambiado bastante.
Hasta este momento solo se ha hablado de proyectos individuales, si pensamos en un entorno profesional donde varios programadores deben de trabajar en un mismo proyecto la complicación crece muchísimo. Imaginad que cada integrante de un equipo tiene sus propias copias de código aisladas de las de sus compañeros. 🤯
¿Que es Git?
Git es un sistema de control de versiones, inventado por Linus Torvalds. Básicamente adaptó el procedimiento que aplicaba cuando aplicaba algún cambio al kernel de Linux 🐧. La idea es tener una linea maestra de la que se pueden ir creando diferentes ramas donde cada desarrollador pueda trabajar sin modificar la versión del software en producción y cuando termine de hacer su tarea, fusionarla con la rama principal.
¿Como saber si tenemos git instalado?
Unicamente tenemos que abrir un terminal y escribir el siguiente comando.
git --versionEn este punto me gustaría comentar una cosa. Si estas leyendo esto debes de ser un desarrollador de software o al menos estar familiarizado con el tema. Tienes que aprender comandos de terminal para trabajar adecuadamente con git. A muchas personas esto les asusta, no les gusta o lo encuentran tedioso (Bueno, puede que las 3 cosas). El caso es no rallarse. Trabajar con los comandos de consola permite tener un control total sobre los cambios que realices en el código y cómo gestionarlos. Sinceramente a mi tampoco me gusta pero no son tantos comandos y también puedes utilizar algunos clientes aunque eso si no tienen todas las funcionalidades. A ver, dedicale un par de horas que no tiene misterio 💪.
Configuración basica
Para poder utilizar de forma apropiada Github y otros servicios que se sincronicen con este es necesario introducir un nombre y correo. Esos datos serán los que aparezcan en todas las aportaciones que haga el usuario. Estos datos pueden introducirse de manera global, es decir, para la totalidad de tus repositorios con el código de abajo.
$ git config --global user.name "<tu nombre>"
$ git config --global user.email "<tu email>"También se pueden introducir estos datos para un repositorio específico. Las instrucciones son las mismas pero sin el parámetro –global.
# Nos posicionamos en el directorio raiz de un repositorio
$ cd <tu directorio de repositorio>
# Introducimos los datos
$ git config user.name "<tu nombre>"
$ git config user.email"<tu email>"Filosofía de Git
el ciclo de vida de Git se divide en 4 etapas que se producen de manera secuencial. Recuerdo que de momento no estamos hablando de Github, eso será en el próximo post.
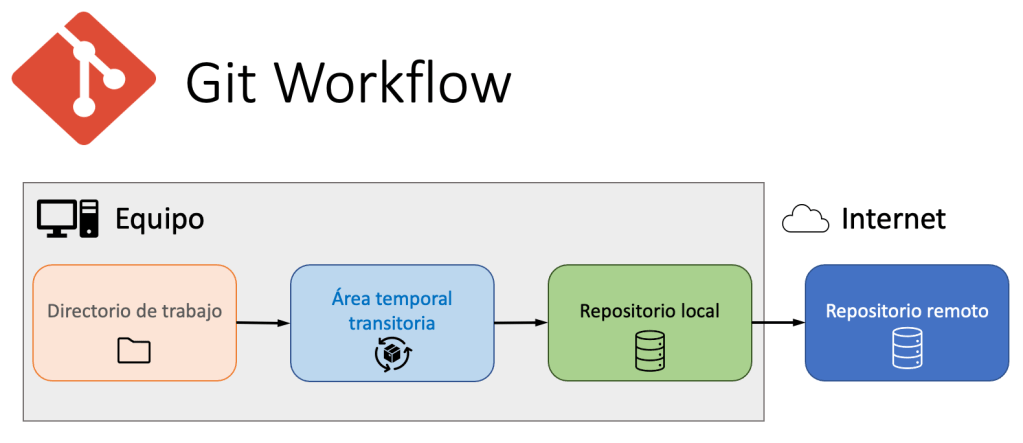
- Directorio de trabajo: Esta es la carpeta raiz de tu proyecto. Este directorio contendrá todos los archivos que se han creado y/o modificado. Además es donde has inicializado el repositorio (donde has ejecutado el comando
git init).
- Area temporal transitoria (Stage area): Git exige indicar que archivos queremos guardar antes de grabarlos en el repositorio local. En muchos casos no vas a querer hacer una copia de seguridad de todo el repositorio, solo de unos pocos ficheros. Además es una medida de seguridad. He de decir que a mí personalmente esto me parecía un poco raro cuando comencé a trabajar con Git pero es muy útil.
- Repositorio local: En esa etapa es donde se va a hacer una foto 📸 de lo que exista en el area temporal y se almacena. También se guardan otros datos muy útiles como el usuario que lo ha grabado (gracias al usuario y el email que hemos introducido al configurar git), la fecha o un identificador único de cada commit (se llama así la operación). Con todo esto Git establece una linea temporal de los cambios que se van guardando en el proyecto y nos permite no solo ir guardando nuestro proyecto sino también volver a un momento anterior por si hubiéramos encontrado un bug o cometido un fallo. Esto es un gran ventaja.
- Repositorio Remoto: Este es el último paso que consiste en subir nuestro código a un repositorio en la nube. Aquí es donde entra en juego Github pero no es la única plataforma que hace esto, existen otros servicios como GitLab por ejemplo. Para poder subirlo el código es necesario configurar un par de parámetros en el repositorio para que Git sepa donde tiene que depositarlo en internet. La instrucción que hace esto se llama
push.
Inicialización de un proyecto en Git
Lo primero que tenemos que hacer para trabajar con Git es crear un proyecto, es decir, un repositorio local, puedes usar el comando git init nombre_proyecto. Esto creará una carpeta vacía con el nombre que le has indicado. Realmente no está vacía ya que contendrá un directorio oculto llamado .git.
Si por el contrario ya has comenzado un proyecto y quieres añadirle git solo tienes que situarte en la carpeta raiz del proyecto y ejecutar el comando git init .
En cualquiera de los 2 casos se habrá creado una rama principal del proyecto llamada main por defecto.
Podemos comprobar si ha ido todo bien con el comando git status. Este comando es muy util, ya que nos muestra cuál es el estado actual del repositorio. Los archivos que se encuentran en el area temporal, si se han hecho commits, etc. Tranquilos que estos términos se explica más adelante.
# Ejemplo de un directorio sin haber inicializado un repositorio
$ git status
fatal: no es un repositorio git (ni ninguno de los directorios superiores): .git
# Ejemplo de un directorio con un repositorio
$ git status
En la rama main
Cambios no rastreados para el commit
sin cambios agregados al commit (usa "git add" y/o "git commit -a")Iniciación a los comandos
Uno de los principales motivos por los que suele causar rechazo Git es por el uso de comandos en la consola, si a esto le unimos la exigencia de comprender el ciclo de vida y que Github tienen una interfaz no tan intuitiva como otras redes sociales se dan bastantes factores como para intentar evitar su uso. Incluso desarrolladores profesionales que conozco me han reconocido que no les gustaba pero cuando han superado esas dificultades les encantó (Cuando he dicho «superar esas dificultades» me refiero a dedicarle 2 tardes con animo de aprender).
Ahora vamos a ver un esquema que nos permita situar que hace cada comando. No voy a profundizar mucho en el código porque el propósito de este post es comprender cómo funciona Git pero si buscáis por Google encontrareis hasta el comando más enrevesado. Esta guía de comandos me parece buenisima. Es super amena, va al grano y el diseño es muy chulo 😽.

git add
Esta instrucción añade tus cambios al área temporal transitoria, lo que significa que estos archivos son monitorizados por Git 🧐. El código está completo, preparado y listo para ser añadido al repositorio.
# Podemos añadir un único archivo
git add nombre_archivo
# Varios archivos
git add nombre_archivo1 nombre_archivo2 carpeta/nombre_archivo3
# Todos los archivos del repositorio que se hayan modificado
git add .git commit
Corrobora los cambios al repositorio. Es frecuente añadir un mensaje (con el flag -m) breve pero detallado acerca de los cambios realizados, si se ha añadido una nueva funcionalidad o arreglado un bug. Esto es muy útil para que el resto de los miembros del equipo entiendan que modificaciones se han hecho, en que parte del código y su causa.
Es importante tener claro que en este comando únicamente guarda todo lo que se encuentre en el área temporal transitoria en el repositorio. Si no queremos subir algún archivo debemos o volver a subir los archivos al área temporal o sacar de esta los archivos que no queramos subir.
Tiene más chicha el comando add que el commit aunque este último es el que compulse los cambios.
# Guardar los cambios en el repositorio
git commit -m "descripción del commit"Ignorar archivos
No deben guardarse todos los archivos que se crean en un repositorio. Muchos archivos (la mayoría) no van a aportar valor añadido alguno a un proyecto y que es una tontería incluirlos en el control de versiones. Los posibles problemas son los siguientes:
- Aumento del tamaño del directorio .git para nada.
- Exposición de valores de contraseñas. Esto es muy común si por ejemplo necesitamos conectarnos a una API.
¿Qué archivos no deben guardarse?
- Dependencias ( 📁
node_modules): Las dependencias pueden descargarse. Esa es una de las ventajas de tener el archivopackage.json - Archivos que tengan API Keys, contraseñas o alguna otra información comprometedora 🔐: Utiliza variables de entorno!
- Logs: 📄No aportan nada
- Covertura del testing ( 📁
coverage) - Carpetas generadas con archivos estáticos (📁
dist) - Carpetas generadas con compilaciones (📁
buid) - Archivos de sistema ⚒️ (
.DS_Store) - Carpetas de configuración de un editor de código (📁
.vscode)
¿Como podemos ignorar estos archivos?
Es muy sencillo, tenemos que crear en el raiz de nuestro repositorio un archivo que se llame .gitignore dentro de este incluiremos los archivos o directorios que queramos omitir. Podemos utilizar wildcards para referirnos a todos los archivos con una determinada extensión. A continuación pongo un ejemplo.
# See https://help.github.com/articles/ignoring-files/ for more about ignoring files.
# dependencies
/node_modules
/.pnp
.pnp.js
# testing
/coverage
# production
/build
# misc
.DS_Store
.env.local
.env.development.local
.env.test.local
.env.production.local
npm-debug.log*
yarn-debug.log*
yarn-error.log*Enlaces interesantes
Aquí está la página de la documentación oficial sobre el archivo .gitignore. Ya veis que no tiene mucha complejidad.
En la web gitignore.io es posible introducir la tecnología que estas utilizando en un proyecto y te crea el archivo .gitignore correspondiente. Para mi gusto el resultado es demasiado grande y pormenorizado pero no significa que esté mal ni mucho menos, eso si, canta que está copiado a tope, aunque eso tampoco me parece que sea algo malo.
Esta página esta muy chula es un buen sitio para aprender y buscar comandos recurrentes, el diseño es muy limpio. Si estas buscando cosas como por ejemplo, sincronizar tu repositorio local con el de Github ese un buen lugar.
⭐️⭐️⭐️⭐️⭐️ Increíble la web learngitbranching.js.org. Explica Git de manera interactiva, con animaciones y lo más importante paso a paso. ¿He mencionado que está en español? Más que recomendable. Cualquier persona que esté empezando con Git debería visitarla sin duda.
